On March 10th, 2020, we held a Data Literacy Consortium Checkin meeting that focused on how we take existing materials and make them work for our contexts and audiences.
Bob Gradeck from the Western Pennsylvania Regional Data Center talked about how they and the Carnegie Library of Pittsburgh adapted exercises put out by MIT’s Civic Media Lab as a way to build their data-101-toolkit, aimed at people staring their journey toward data literacy. Instead of having computer-based workshops, they decided to move to paper-based activities. They found that people talked to each other when computers weren’t involved and were able to grasp concepts more quickly. Paper also helped to “level the playing field” between data experts and beginners. They tested the toolkit throughout the Pittsburgh region, and developed a detailed facilitators guide for others that contained instructions in how to use and modify the activities and materials for different contexts.
Because Bob has been participating in the consortium and shared links to the Data 101 Toolkit in our check-in meeting roll calls – Lisa and Katelyn at the Centre for Humanitarian Data picked up the Data 101 Toolkit. They were inspired to modify the activities and develop their materials to help humanitarians become more data literate. The facilitator’s guides were essential in assisting them in adapting training materials for new audiences. They wanted to provide humanitarians with a way to feel like the design of the workshops and data used in the activities were relevant to their work and organisation.
Dirk talked about how he was inspired by School of Data’s Data Pipeline to create a ‘put steps in order’ exercise for people to reflect on whether or not their data workflows were linear like the pipeline or if there are cycles within.
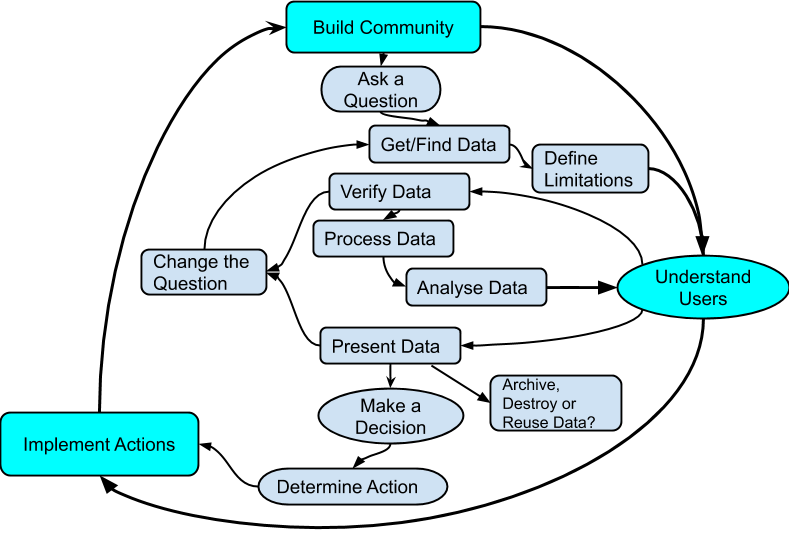

Find it here:
- A Data Strategy Workshop Curriculum – https://www.fabriders.net/data-strategy-curriculum/
- In the Data Playbook (Beta): https://www.preparecenter.org/sites/default/files/exercise2putdataprojectitemsinorder110618.pdf
Heather discussed how after IFRC released the Data Playbook beta, they wanted to spend more time understanding their audiences before they started working on the V1. They started by working on co-creating a module on Data Literacy for Volunteers. It’s also been critical for her to interact in the Data Literacy Consortium to understand how people use and adapt existing materials, and she drove home how this is the core reason for its existence.
Heather discussed how, after IFRC released the Data Playbook beta, they wanted to spend more time understanding their audiences before they started working on the V1. They began by working on co-creating a module on Data Literacy for Volunteers. It’s been vital for her to interact in the Data Literacy Consortium to understand how people use and adapt existing materials. She drove home how this is the core reason for its existence.
We then sent participants into small group breakouts to discuss their own experiences in adapting materials for their data literacy efforts. Some takeaways from those discussions:
- There are tons of resources to go through.
- You need to be able to build workshops that are not data first to reach people. Look to train people who are not self-described as ‘data people’.
- There’s a lot of value in translating stuff that happens in tech to paper and sometimes even dirt!
- Organisations need to create holistic frameworks to build different audiences.
- Repurpose materials, identify gaps in materials, how to help people discover the resources.
- Know the best way to get stuff to your audiences, e.g. a podcast for fishers.
- Do we need a dataset of data literacy materials? With excellent tagging?
Resources that came up:
- Data 101 Toolkit: https://www.wprdc.org/news/data-101-toolkit/
- Civic Switchboard Guide https://civic-switchboard.gitbook.io/guide/
- Data Playbook (Beta) https://www.preparecenter.org/toolkit/data-playbook-toolkit
- Civicus Research and analysis on citizen generated data: https://www.civicus.org/thedatashift/learning-zone/research
- State of Open Data: https://stateofopendata.od4d.net/
- Building Evaluation Capacity
- US Census Bureau’s Statistics in Schools
- Storytelling With Data,
- Show Me the Numbers,
- Effective Data Visualization
- Hands-On Guide to Participatory Data Analysis
- U. Chicago Data Maturity Framework
- The draft data readiness toolkit. Building out relevant resources on this page.
We are grateful to everyone who participated:
- Marilyn Pratt, Independent consultant
- Anna Cooper, British Red Cross
- Eva Ghirmai, American Red Cross
- Liselot Kattemölle, Dutch Red Cross
- Kate Wing, Intertidal Agency
- Bob Gradeck. Western Pennsylvania Regional Data Center/ University of Pittsburgh
- Steve Kenei, Kenya Red Cross Society
- Thuong Nguyen, British Red Cross
- Sarah Eisele-Dyrli, Connecticut Data Collaborative, Connecticut State Data Center
- Joel Myhre, Pacific Disaster Centre
- Hannah Wheatley, CIVICUS
- Lara Horstmann, United Nations DPPA-DPO Information Management Unit
- Neil Planchon, Foundation for Intentional Community (ic.org), NTEN Oakland, CiviCRM, WordPress…
- Yusuf Suleiman. Youthmappers
- Liz Monk, Western Pennsylvania Regional Data Center/ University of Pittsburgh
- Heather Leson, IFRC
- Lisa Peterson, Centre for Humanitarian Data
- Katelyn Rogers, Centre for Humanitarian Data
- Dirk Slater, FabRiders
Here’s the video of the discussion


{kind=link}